1. Introduction
The application of speech recognition and machine translation for automatic subtitling emerges as a promising solution. By providing real-time subtitles, viewers can understand and engage with the content in their preferred language. SwapBrain’s video subtitle generator provides a solution by enabling users to watch videos with auto-generated, translated subtitles.
In this article, we present a real-time video subtitle generator, implemented as a Chrome extension, to seamlessly translate and caption videos as you watch.
2. Architecture Design of an Advanced Video Subtitle Generator System
The system architecture is designed to ensure efficient and real-time processing of video content for automatic subtitling. The key component of the architecture is shown in the sequence diagram.
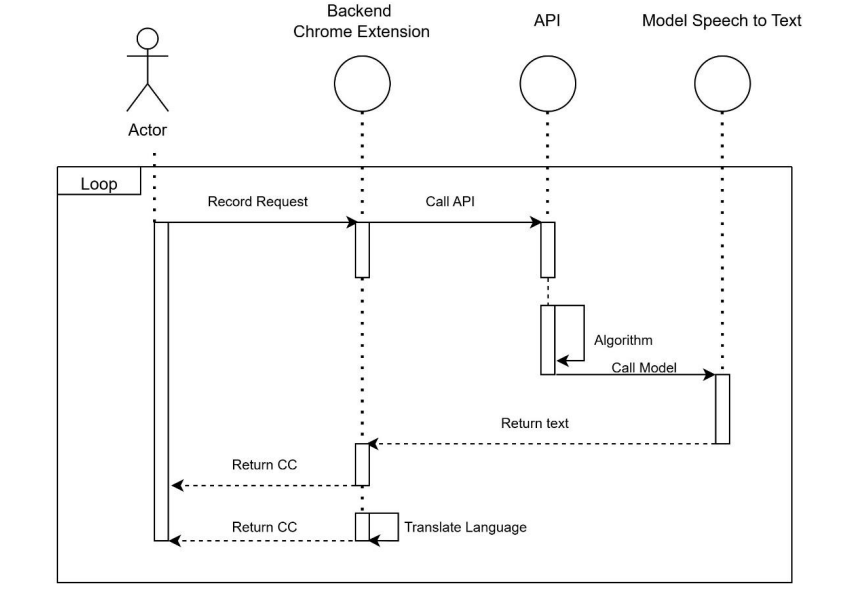
Figure 1 – The sequence diagram of system
3. Experimental Results: Enhancing Accessibility with a Video Subtitle Generator
In this part, we want to clarify more about the models and transmission methods. A note here is that the transmission method to the server is still via API call (we will clarify this further in section 4), while transmission to the client will be a comparison between REST API and WebSocket.
3.1. Comparison of Approaches: REST API vs. WebSocket Method
3.1.1 Transmission Methods Between Client and Server
a. Rest API Method
I measured the time from when the text was displayed until the result was received and displayed in the browser. This experiment was performed 10 times and the results of each measurement are shown on the graph. The time measured at each time fluctuated, but the average was 741.2 milliseconds (ms). The graph illustrates the variation of response time over 10 measurements.
For example, if the chart is a line, we can see the changing trend of the response time, and if it is a column chart, each column will represent the response time of each measurement. An average of 741.2 ms was calculated by summing the times of the 10 measurements and dividing by 10, giving a number that represents the average response time.

Figure 2 – The Bar Chart Analysis of RestAPI Performance in a Video Subtitle Generator
In the chart above, you can see that the average time the RestAPI returns is around 741.2 milliseconds. The bar chart shows the model runtime (in milliseconds) measured over 10 different times. The runtimes varied significantly between measurements, with a minimum of 609 ms and a maximum of 889 ms. The majority of runtimes were around 700 ms, with a few exceptions exceeding 800 ms and one below 650 ms.
Measurements 5, 8, and 10 had significantly higher runtimes than the others, indicating variability in model performance under certain conditions. The highest runtime was observed at measurement 5 (889 ms), while the lowest runtime was at measurement 8 (609 ms). Measurement 10 also had a high runtime (837 ms). Most of the measurements (1, 2, 3, 4, 6, and 7) were relatively consistent, ranging from 706 ms to 760 ms. 1
b. WebSocket Method
WebSocket is a communication protocol that provides full-duplex communication channels over a single TCP connection. Unlike REST APIs, which follow a request response model, WebSocket allows for persistent connections, enabling real-time data transfer between the client and the server. This makes WebSocket particularly useful for applications that require constant data updates, such as live chat applications, online gaming, or real-time trading platforms. WebSocket connections begin with a handshake process, after which data can be sent back and forth between the client and server without the overhead of opening new connections for each message.
Figure 3 – WebSocket Connection
In terms of transmission and reception time, WebSocket offers significantly lower latency. Because the connection remains open, data can be sent and received almost instantaneously, which is ideal for real-time applications. According to actual results, the average time after returning the text result until the text appears on the front end is 0.37 milliseconds.
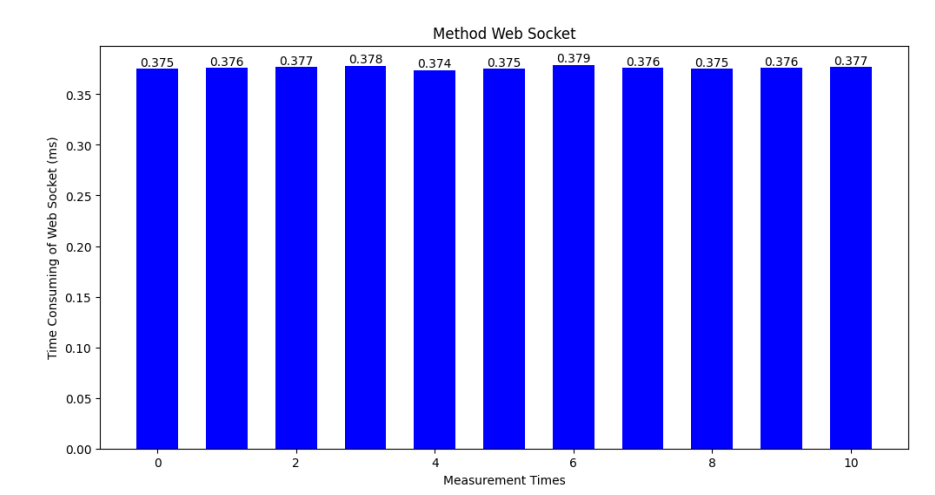
Figure 4 – The Bar Chart Analysis of WebSocket Performance in a Video Subtitle Generator
c. Conclusion
The comparison between the REST API and WebSocket methods highlights a significant difference in the transmission and reception times. The REST API method, which involves establishing a new HTTP connection for each request, results in an average latency of 760 milliseconds. This delay can be detrimental to applications requiring real-time data updates, as it can hinder user experience by introducing noticeable lags.
On the other hand, the WebSocket method, which maintains a persistent connection, boasts an average latency of just 0.37 milliseconds. This near-instantaneous data transmission makes WebSocket highly suitable for applications that demand real time interaction and immediate data synchronization, such as live chat, online gaming, or real-time trading platforms.
Decision: WebSocket is the clear choice due to its low latency of 0.37 milliseconds. The persistent connection ensures that data is transmitted almost instantaneously, providing a smooth and responsive user experience.
3.1.2 Comparing Speech-to-Text Models: Vosk vs. Google Speech Recognition for a Video Subtitle Generator
Speech-to-text technology has advanced significantly, with various models offering different capabilities and performance metrics. This section compares two popular speech recognition models: Vosk and Google Speech Recognition. Both models convert spoken language into text but differ in design, performance, and use cases.
a. Google Speech Recognition Model
Cloud-Based Solution:
- Google Speech Recognition operates as a cloud-based service. Users send audio data to Google servers, where powerful algorithms process the data and return the text results.
- This cloud infrastructure allows for high accuracy due to access to vast amounts of training data and sophisticated machine learning models.
Continuous Updates:
- Being a cloud-based service, Google can continuously update and improve the model without requiring users to update any software on their end.
- This ensures the model stays current with the latest advancements in speech recognition technology
Latency:

Figure 5 – The Scatter Graph Analysis of the Google Recognition Model in a Video Subtitle Generator
The scatter plot gives us an overview of the relationship between audio length (in seconds) and model runtime (in seconds) for Google Recognizer. Each data point on the plot represents a specific audio sample, with audio length on the x-axis and the time it took the model to process that audio on the y-axis. For short sounds (about 1 to 2 seconds), the data points are densely concentrated, indicating that the model processes these short audio segments quite quickly, usually under 2 seconds.
As the audio length increases (about 3 to 6 seconds), the distribution of running times becomes more diverse. Some audio files have similar lengths but have different processing times, indicating differences in the complexity of the audio content or other factors affecting processing time. In addition, the most suitable time to return results is about 1s to 3s, and processing by Google Recognition to recognize new words every 1s will have different results return times.
b. Vosk Model
Vosk is an open-source speech recognition toolkit that allows for local deployment. This means the model runs entirely on the user’s device without requiring internet connectivity. This design is advantageous for privacy-sensitive applications and scenarios where internet access is limited or unreliable. 2
Lightweight and Efficient:
- Vosk is designed to be lightweight and efficient, capable of running on various devices, including those with limited computational resources.
- It uses efficient neural network architectures optimized for local execution, making it suitable for embedded systems and edge devices.
Latency:

Figure 6 – The Scatter Graph Analysis of the Vosk Model in a Video Subtitle Generator
Vosk’s local execution results in significantly lower latency. The average time for transcription 1 audio equivalent 1 second is around 0.15 seconds.
c. Conclusion
Latency and Response Time:
- Google Speech Recognition has an average latency of 1.5 seconds due to the cloud communication overhead. The SpeechRecognition documentation recommends using a duration no less than 0.5 seconds. In some cases, you may find that durations longer than the default of one second generate better results. This may be acceptable for many applications but can be a drawback for real-time use cases.
- Vosk, with its local processing, offers a much lower latency of 0.25 seconds, providing near-instantaneous results suitable for real-time applications.
Running Time vs. Audio Length:
- The provided graphs illustrate the model running time versus audio length for both Google Speech Recognition and Vosk.
- Google Speech Recognition’s running time increases significantly with longer audio lengths, reflecting the cloud processing overhead.
- Vosk demonstrates a more consistent running time, with much lower variability, due to local execution.
Decision: Vosk is preferable for applications needing real-time performance, privacy, and offline capabilities. The significantly lower latency of Vosk (0.25 seconds) compared to Google Speech Recognition (1.5 seconds) highlights its advantage in real-time applications.
3.2 The combination of Vosk Model and WebSocket Transmission
3.2.1 Latency
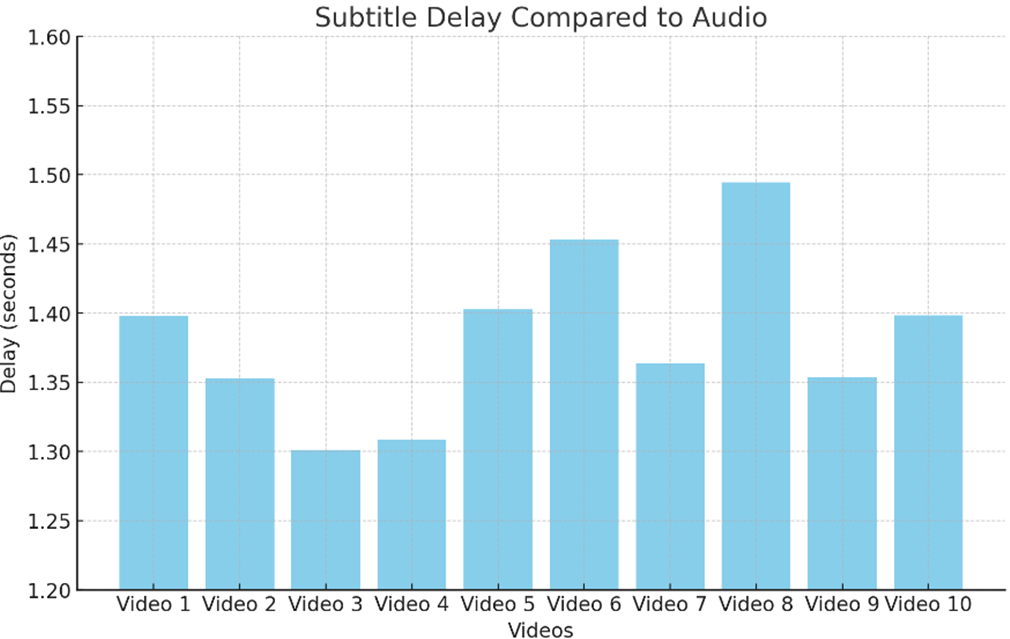
Figure 7 – Addressing Latency Between Audio and Subtitles in a Video Subtitle Generator
Given that all delays are within 1.3 to 1.5 seconds, they are considered acceptable and should not significantly impact the viewing experience.
3.2.2 The Quality of Transcription
| Sentence displayed on Screen | True Sentencte | Order Sentence |
| i’m milton | I’m Milton | Sentence 1 |
| i’m milton could you tell | I’m Milton, could you tell | Sentence 2 |
| milton could you tell me how i can get then | Milton, could you tell me how i can get there | Sentence 3 |
| could you tell me how i can get their mill | could you tell me how i can get there mill | Sentence 4 |
| how i can get their milton did you say | how i can get there, Milton, Did you say | Sentence 5 |
| milton did you say let me see | Milton did you say let me see | Sentence 6 |
| did you say let me see i think that’s | Did you say let me see i think that’s | Sentence 7 |
| let me see i think that’s about one hundred and | let me see i think that’s about one hundred and | Sentence 8 |
| i think that’s about one hundred and fifty miles south | i think that’s about one hundred and fifty miles south | Sentence 9 |
| bowed one hundred and fifty miles southwest of here | about one hundred and fifty miles southwest of here | Sentence 10 |
3.3 The combination of Google Recognition and RestAPI Transmission
3.3.1. Latency

Figure 8 – Addressing Latency Between Audio and Subtitles in a Video Subtitle Generator
The average latency is 3.77, this is quite a large latency, so it greatly affects the user experience. This cloud-based service provides highly accurate transcription but can suffer from higher latency due to network transmission times. It generally takes a few hundred milliseconds to process the speech and return the transcription.
3.3.2 The Quality of Transcription
| Sentence displayed on Screen | True Sentencte | Order Sentence |
| to a town called Milton | to a town called Milton | Sentence 1 |
| Milton could you tell me how | Could you tell me how can I get there | Sentence 2 |
| could you tell me how I can get there | Could you tell me how can I get there | Sentence 3 |
| Milton Milton did you say | Milton did you say | Sentence 4 |
| let me see I think that’s | Let me see I think that’s | Sentence 5 |
| I think that’s about 150 miles | about 150 miles Southwest of here | Sentence 6 |
| miles Southwest of here list of here | that’s about 150 miles Southwest of here | Sentence 7 |
| in fact it’s it’s 147 | In fact it is 147 miles to be exact | Sentence 8 |
| 147 me to be exact | In fact it is 147 miles to be exact | Sentence 9 |
| so it’ll take you at least say | so it’ll take you at least say | Sentence 10 |
Table 2 – The table of Transcription
4. Optimization of a Video Subtitle Generator Using Python and WebSocket
Based on the above experiments, we can clearly demonstrate that REST API is not suitable for real-time translation. Therefore, in the optimization step, we need to switch the transmission method to the server to WebSocket. Although the optimization process is not yet complete, we can prove that transmitting the audio signal to the server via WebSocket significantly reduces latency. This is evidenced by developing a simple real-time translation recording application, and its translation time is illustrated in the following chart:

Figure 9 – Reducing Latency Between Audio and Subtitles in a Video Subtitle Generator
Clearly, the latency is extremely low, averaging only around 0.2 seconds, which is quite an impressive figure for real-time automatic translation.
5. Conclusion
In conclusion, the combination of the Vosk speech recognition model with WebSocket transmission proves to be the optimal solution for real-time automatic subtitling. WebSocket’s low latency ensures near-instantaneous data transfer, while Vosk’s local processing provides quick and accurate transcription. This setup effectively addresses the challenges of language barriers in global media consumption, enhancing user experience with reliable and timely subtitles.
\Ready to see it in action? Visit SwapBrain now and discover firsthand how our powerful tools can transform your videos. Don’t miss out—experience it for yourself today!

